For a while now with the Cimes team we have been considering building a composer's tool to write audio-visual pieces for Cimes. That idea had come from the hassle of writing hundreds of sound-shape associations and positions directly to an XML file when writing a first piece... I have recently started to work on it for real, and I'm very excited about it :)


First, a quick reminder of Cimes' essentials (smallab.co/cimes) :
- Cimes is a musical score and an instrument at the same time.
- It is a software tool that allows a performer in playing and interpreting both in time and musical sense an electroacoustic music piece with a joystick or a Wiimote, for an audience, with both audio and visual outcomes.
- It is based on a simple idea : associating a shape with a sound sample and placing those on a map which can be browsed through for interaction.
This "Cimes composer's software" can be accomplished in several ways, here are two, one of which I'm about to follow :
- As it's been first tested out with the pilot piece "Énigme" where the music was put together by sound artist Éric Broitmann and the visuals and their motion/behavior by myself, there is always the "one by one" way : shapes and sound samples are both produced by hand. That works well and can be artistically rewarding, since obviously the whole experience/performance of the score/instrument is very finely tuned in that manner. Building a composer's tool with this workflow in mind would typically result in enabling a composer+designer team to work on a canvas where they could drag and drop shapes and sounds that they would pick from files which they would have produced prior to this composition time, with their own tools (Protools and Photoshop...). Of course that wouldn't be the quickest way. Nonetheless a pretty sure way.
- An interesting, alternate approach to organizing the workflow could be to consider that, as it has actually happened with the pilot piece, sound will always come first in Cimes. Therefore when a music piece is complete, when all sound samples have been calibrated and placed on a timeline, then comes the time of representing them visually. Now that makes room for a whole new set of possibilities : what if (for example ;) a software would analyze each and every one of the sound samples and produce their corresponding shapes by following a set of rules, tweaked by its user ?
Come in CataRT by Diemo Schwarz (IMTR, Ircam), and Swirls for CataRT by myself at USER STUDIO (ANR partly funded project "Topophonie") :
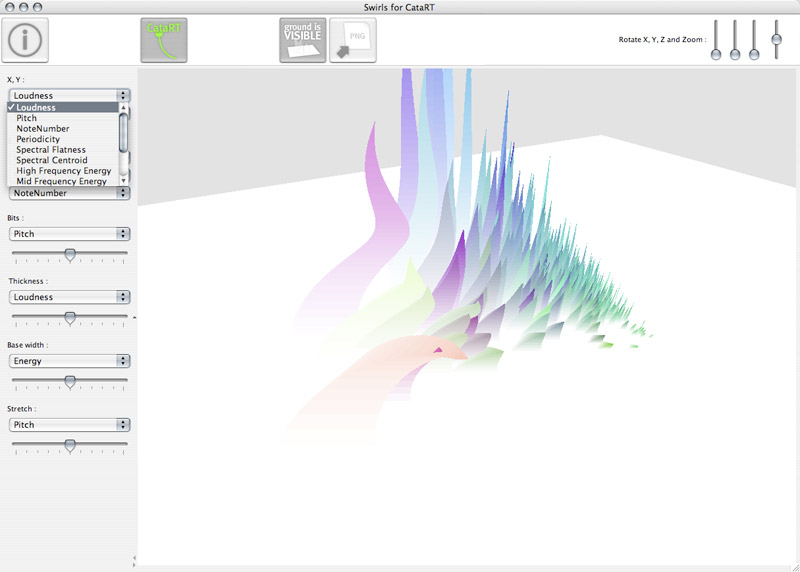
« "Swirls for CataRT" represents a corpus of sounds, imported, segmented, and analysed by CataRT in a 3D space as shapes of "swirls", a sort of spiralling grass that grows according to the analysed sound descriptors. The swirl space can be navigated interactively with the mouse to trigger playing of the units. The corpus-based concatenative sound synthesis system CataRT plays grains from a large corpus of segmented and descriptor-analysed sounds according to proximity to a target position in the descriptor space. This can be seen as a content-based extension to granular synthesis providing direct access to specific sound characteristics. »
To get a quick overview of the CataRT + Swirls for CataRT combination, watch the following video screenshot (previous version 0.15) :
This software will allow for a logical, automatic production of visual representations of each sound sample that the music comprises. Logic aside, the automation part of the process must be designed in such a way that it will fit the purpose of producing an easthetically pleasing experience when being played with Cimes. Parameters must be chosen so that shapes will defer in a meaningful way from one another. And playback feedback in Cimes must be linked with the produced shape : explosion in hundreds of bits... Clusters of 3d shapes such as the ones produced by Swirls for CataRT are likely to fit that purpose quite well : giving a granular representation of electroacoustic sound samples that are bound to be disintegrated into fragments.
The "swirl" is obviously only an example of 3d model that may be used. Indeed, typically an electroacoustic music piece will bear several families of sounds, so it might be interesting to translate those to plural kinds of visuals. Swirls for CataRT would need to evolve to withstand that new goal : Shapes for CataRT. Let's see how that goes in the coming months.
